「データベース設計って何に気をつけてやれば良いんだろう?」「データベース設計の基本的な手順が知りたい」
こんなふうに思ったことはないだろうか。
筆者はエンジニア2年目の時に複数のデータベースのテーブル追加を伴う案件を任され、どのように進めるのが良いのかわからずかなり困惑した記憶がある。どう進めれば良いか全くわからず、結果として設計レビューではかなりの指摘を受けた。なんどもなんども修正とレビューを繰り返した記憶がある。
そのため、この記事では初めてデータベース設計をする方が同じような苦い経験をすることがないように、筆者が当時知っておきたかったことをまとめた。主にアプリケーション開発でメインになるデータベースの論理設計について話していく。
基本的なデータベースの設計手順としては以下の6段階だ。
1エンティティを洗い出す
2エンティティに項目を入れていく
3データの重複を排除する(正規化)
4エンティティ間の関連を定義する
5ビジネス要件を実現できるか確認する
6導出項目を排除する
このやり方をECサイトの例をもとに本文では紹介していく。
また、代表的なアンチパターンをその具体例となぜいけないのかについても説明する。それによって設計の勘所が少しでも見えてきてくれたら幸いだ。
では、実際に見ていこう。
1エンティティを洗い出す
まずはデータとして登録するエンティティを特定する。エンティティとはデータの集合のことである。
データベース設計においては、エンティティには以下の二つがある。
・イベント(ECサイトで言うと、注文、配送など)
・リソース(ECサイトで言うと、商品、ユーザーなど)
まずはイベントを洗い出し、その後にリソースを特定する流れが効率的だ。
続く章で詳しく説明していく。
1−1イベントを洗い出す
まずはイベントを洗い出す。ECサイトで言えば注文などの行動のことだ。
イベントを見分けるには、「いつ(タイムスタンプ)」を属性として定義できるかを検討するとわかりやすい。
なぜ最初にイベントを特定するかと言うと、漏れなく把握しやすいからだ。例えば業務内容をヒアリングする際も、やってること(イベント)を聞き出す方が、どんなもの(リソース)を扱ってるかを聞くより圧倒的に簡単だ。
エンジニアの業務で考えてみるとわかりやすい。使っているリソースはソースコード、GitHubなどのバージョン管理ツールや、チャットツールがあるかもしれない。しかし、それを網羅するのは難しい。それよりも、チケットを見て、コードの実装をして、テストをして、レビューしてもらってというイベントの方が抜け漏れなく伝えられるのではないだろうか。
ここを手掛かりに設計を進めていくことで、必要になるその他の情報も見つけやすくなる。
先ほどのエンジニアの例で言えば、チケットの管理ツールや、コードの実装に必要なエディタもリソースとして認識することができる。
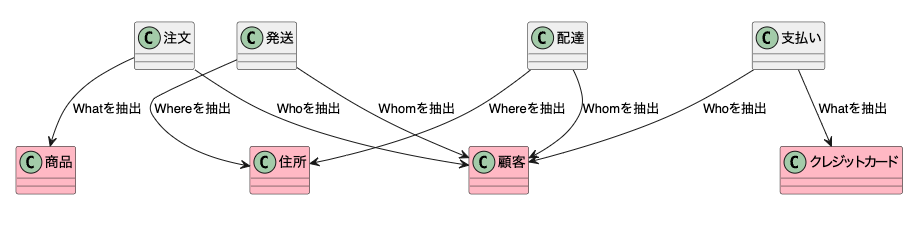
ECサイトを例にしてみると、一番管理したいのは注文と発送、配送、支払いだ。

1−2リソースを洗い出す
次にリソースを洗い出す。ECサイトで言えば商品などのことだ。
リソースを見分けるには、名刺で言えるかを考えるとわかりやすい。
具体的には、先ほど特定したイベントに必要となる情報を特定していく。例えば、「注文」には「誰が」「何を」注文すると言う情報が必要だ。また「発送」と「配達」には「誰に」と「どこに」が必要だ。そして「支払い」には「誰が」「何で」が必要だ。(ここでは簡易的に支払いはクレカのみを想定している)
それらを特定したのが下の画像だ。
2エンティティに項目を入れていく
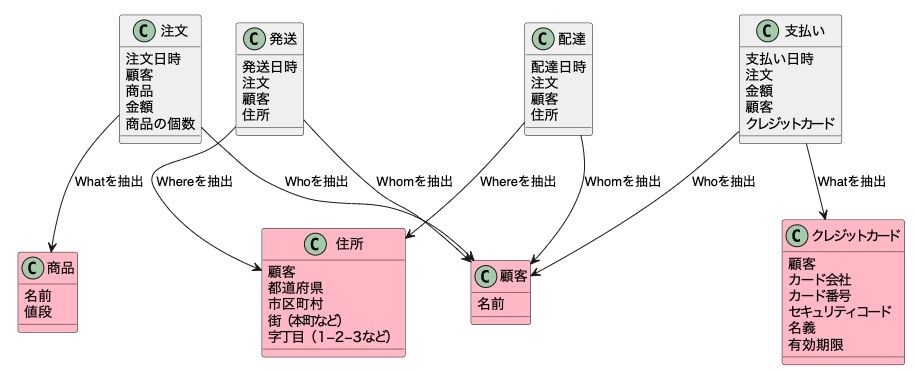
エンティティの抽出が終わったら各エンティティに必要な項目を入れていく。例えば、商品であれば「商品名」が項目として必要だ。
それらを行ったのが以下の図である。
3データの重複を排除する(正規化)
項目が各エンティティに入ったら、データの重複を排除するために正規化をする。正規化の目的を簡単に言うと、1つの事実を1つの場所にだけ保管しておくためだ。こうすることでデータの不整合が起きるのを防ぐ。
正規化のやり方については詳しくはこちらの記事を参照してほしい。
失敗しないデータベース正規化の3ステップをプロのエンジニアが解説
正規化をした結果、以下の画像のようになった。
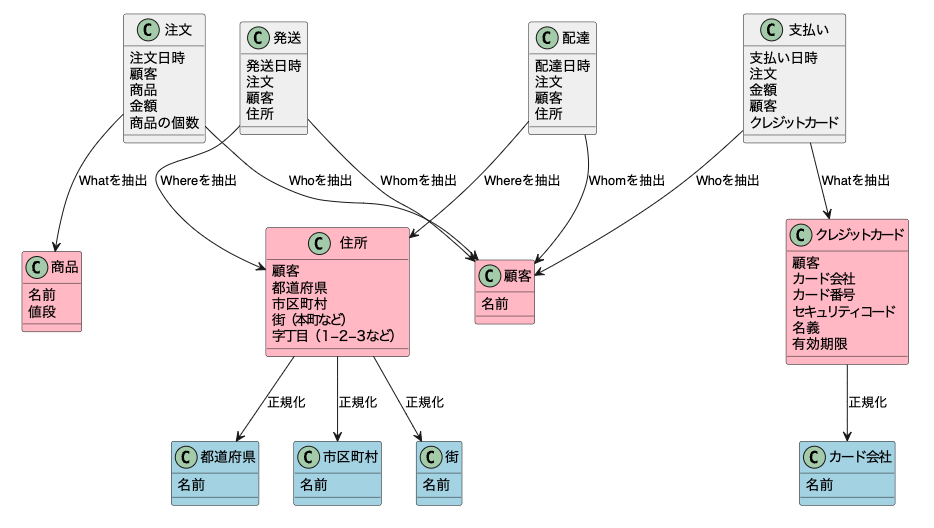
この例では、以下の二つを正規化した。
・住所テーブルの都道府県や市区町村の値
・クレジットカードのカード会社
それらをテキストで管理するのではなく、マスターデータを用意してそちらを参照するようにした。
4エンティティ間の関連を定義する
エンティティ間の関連を定義する。
関連には以下の3つの種類がある。それぞれどう言う時に使うかを説明していく。
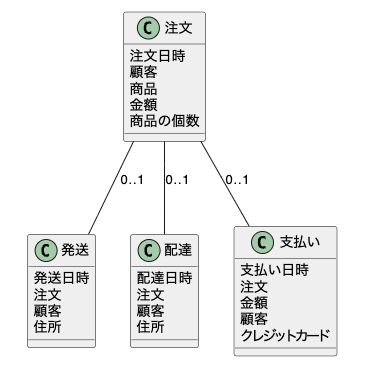
4−1一対一
まずは一対一だ。Aテーブルのレコードと、Bテーブルのレコードがあるとしよう。この時、AはBとだけ紐づいていて、BもAとだけ紐づいているパターンだ。
例えば、ECの例で言えば注文に対する発送や支払いなどで使われることがある。該当のレコードがなければ、まだ実行されていないなどといった判定ができる。
4−2一対多
次は一対多だ。著者とその著作物を考えるとわかりやすい。つまり、一人の著者に複数の著作物が紐づいている状態だ。
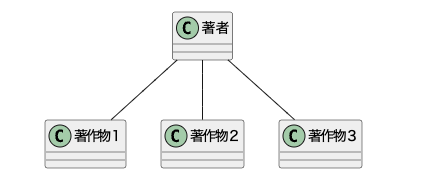
ER図で書き表すと以下のようになる。(三つ足に見える部分が多数からの紐付き、を所有することを表している)

ECサイトの例で言うと以下のようになる。
4−3多対多
最後は多対多だ。オンライン学習講座のサイトを考えるとわかりやすい。受講者は複数の講座を取れるし、講座は複数の受講者を持つことができる。
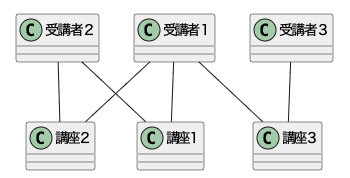
ER図で書き表すと以下のようになる。三つ足が受講者からも講座からも出ているのがわかる。

ECサイトの例で言うと、先ほどの商品と顧客が注文テーブルを介して多対多の関係になっていた。
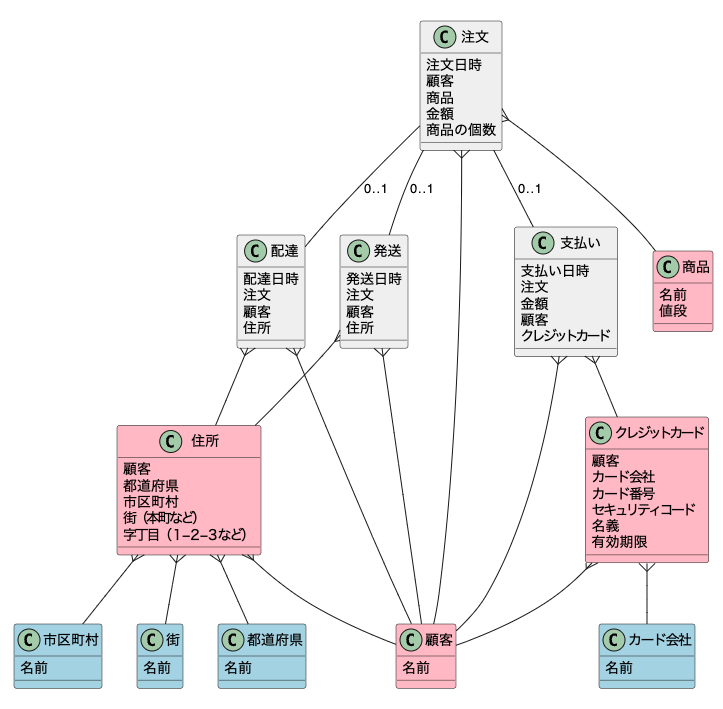
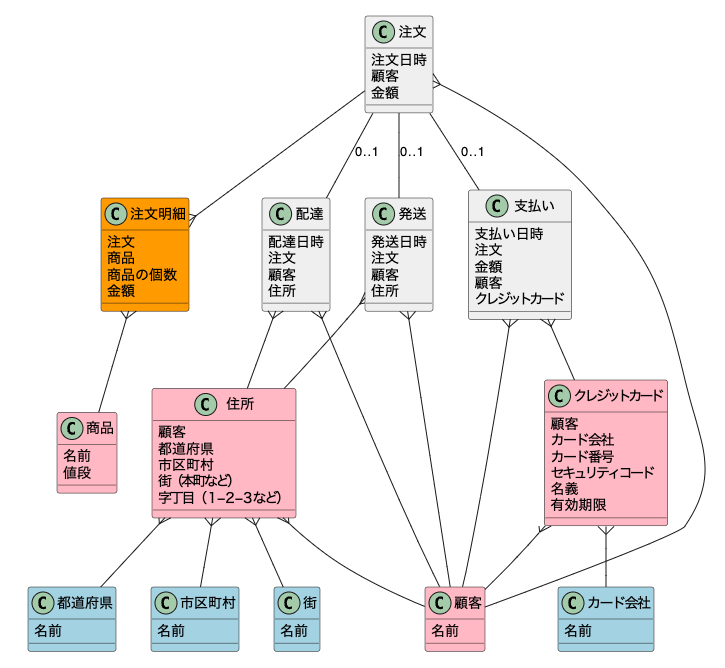
5ビジネス要件を実現できるか確認する
ここまできたら、一旦今の構造でビジネス要件を満たせているかを確認する。現状のER図は以下の通りだ。
5−1各エンティティの紐付きを確認する
よく筆者がやる確認方法としては、各エンティティ間の紐付きをチェックする。例えば、「顧客」から出ている関連が正しいかを見る。
・顧客は複数の住所を持てる
・顧客は複数の配達を受けられる
・顧客は複数の発送を受けられる
・顧客は複数の注文ができる
・顧客は複数の支払いをできる
・顧客は複数のクレジットカードを持てる
5−2不足がある場合は修正する
チェックを続けていくと、一つの「注文」レコードは1つの顧客と1種類の商品しか関連付けられないことに気づく。つまり、複数種類の商品を一度に注文できないということだ。
これは意図した作りではない。そのため、一度の注文で複数の商品を選べるようにする。
方法としては、注文と商品の間に注文商品というテーブルを作る。そして、「注文」は複数の注文商品を持てるようにする。こうすることで、複数種類の商品を一つの注文で管理できるようになった。
考え方としては以下の通りだ。
| 手順 | やること | 画像 |
|---|---|---|
| 1 | 正規化しない状態でやりたい変更をする |  |
| 2 | 正規化する | 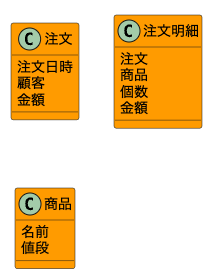 |
| 3 | 関連付けする |  |
結果として全体的には以下のようになった。
6導出項目を排除する
ここでは導出項目を排除していく。
導出項目とは、複数の値を使って算出することが可能な値のことだ。
6−1よくある導出項目の事例
例えば、以下のようなテーブルを考える。

この時、年齢が導出項目である。生年月日と現在時刻が分かれば年齢は算出できるからだ。そのため、年齢という項目は排除することになる。
また、ECサイトの例で言えば、商品の価格が常に一定である場合を考えてみよう。

この場合は「注文」「注文明細」の両方のテーブルの「金額」は導出項目として排除する。これらの値は、常に以下の順序で求められるからだ。
・注文の金額:「注文明細数 x 注文明細ごとの金額」
・注文明細の金額: 「商品の単価 x 個数」
6−2要注意な特殊ケース
要注意なのは、導出項目の算出元の値が一定ではない可能性がある場合だ。
ECサイトの例であれば、商品価格が変更されうる場合だ。セールなどで一時的に商品の価格が変動する場合が考えられる。
この場合も前の章と同様に、「注文」「注文明細」の両方のテーブルの「金額」は導出項目として排除できる。
しかし、前の章と違うのは、商品の値段がタイミングによって異なるという情報を管理する仕組みが必要になる点だ。

ただし、注文履歴画面などで「過去の注文額を一覧表示する」場合にデータの計算量が不要に大きくなる可能性もある。そういうことを考慮すると、あえて注文明細には金額を残す判断もあり得る。そうすることで計算量を抑えることができるからだ。
まとめ
データベース設計の手順について6つのステップに分けて解説してきた。
特にエンティティについてイベントとリソースに分けて抽出する考え方や、導出項目の排除の時の考え方はしっかり覚えてもらえると良いと思う。
エンティティ抽出については、ざっくりと考えるよりも基準を分けて考える方が取り組みやすいと思うからだ。
また導出項目の排除の方については、データモデリングが業務要件をヒアリングするきっかけにもなるということが理解してもらいやすいと思うからだ。
この記事がデータベース設計の手順で悩む読者の方の課題解決に寄与できていたら幸いだ。